
最近有朋友叫我帮忙部署一个影音转文档的开源工具,属于一键将音视频转化为小红书/公众号/知识笔记/思维导图/视频字幕等各种风格的文档。看了下后端依赖于字节跳动火山引擎,所以会产生一些费用,实际试用费用还好。
Docker部署
按照文档,选择用docker部署更快:
0️⃣:安装 docker, 这个网上有教程。
1️⃣:镜像构建, 在项目根目录下执行:
Note: 最好有代理加持,不然过程会很痛苦。
$ make docker-image2️⃣:这一步很重要,请根据 后端部署指引 / 配置项说明 完善根目录下的 variables.env 文件。下面也写了详细的配置获取方法。
3️⃣:运行项目,在项目根目录下执行:
$ make run
在火山引擎获取对应的环境变量的值
主要分为三部分, 火山方舟/字节Tos/音频识别大模型
火山方舟
MODEL_ID
⚠️: 最新版本的 AI-Media2Doc 已经不再需要 ENDPOINT_ID, 由 MODEL_ID 代替。
登录方舟控制台。进入开通管理, 选择开通一个大语言模型。 推荐使用 doubao-1-5-pro-32k-250115 。点击开通之后点击该大模型进入详情页,选择通用 LLM(没有就选主线模型), 复制红框内的 模型 ID,即为 MODEL_ID 的值。

ARK_API_KEY
在 API Key 管理中创建一个 API Key 参考文档 你就得到了 ARK_API_KEY 的值。
火山引擎对象存储服务
创建 bucket 设置跨域规则
登录对象存储控制台 创建一个 bucket, 创建完毕之后进入该 bucket。点击右侧权限管理, 找到跨域访问设置, 新建一条跨域访问规则。

当然你也可以根据实际情况灵活选择。
TOS_ENDPOINT
点击 桶列表 -> 点进去你创建的那个 bucket -> 点击概览 -> 眼睛往下看
你会看到一个访问域名, TOS_ENDPOINT 的值就是红框框里面那个,不同的区域 TOS_ENDPOINT 的值可能不一样。

TOS_BUCKET
TOS_BUCKET 的值就是你创建的 bucket 的名称。
TOS_REGION
TOS_REGION 的值就是你创建的 bucket 的区域, 例如 cn-beijing。
TOS_ACCESS_KEY 和 TOS_SECRET_KEY
进入 IAM控制台 创建一个访问密钥, 你就得到了 TOS_ACCESS_KEY 和 TOS_SECRET_KEY 的值。
音频识别大模型
火山方舟每个音频识别大模型都提供了 20 个小时的试用额度, 可以轮流试用。
登录录音文件识别大模型控制台(https://console.volcengine.com/speech/service), 点击右侧录音文件识别, 创建一个应用, 你就得到了 AUC_APP_ID 和 AUC_ACCESS_TOKEN 的值。
AUC_APP_ID
AUC_APP_ID 的值就是你创建的应用的 ID。
AUC_ACCESS_TOKEN
AUC_ACCESS_TOKEN 的值就是你创建的应用的 Access Token。
AUC_CLUSTER_ID
点击试用 录音文件识别-通用-标准版 或者其他的大模型,开通试用之后,Cluster ID 列就表示 AUC_CLUSTER_ID 的值。
效果图

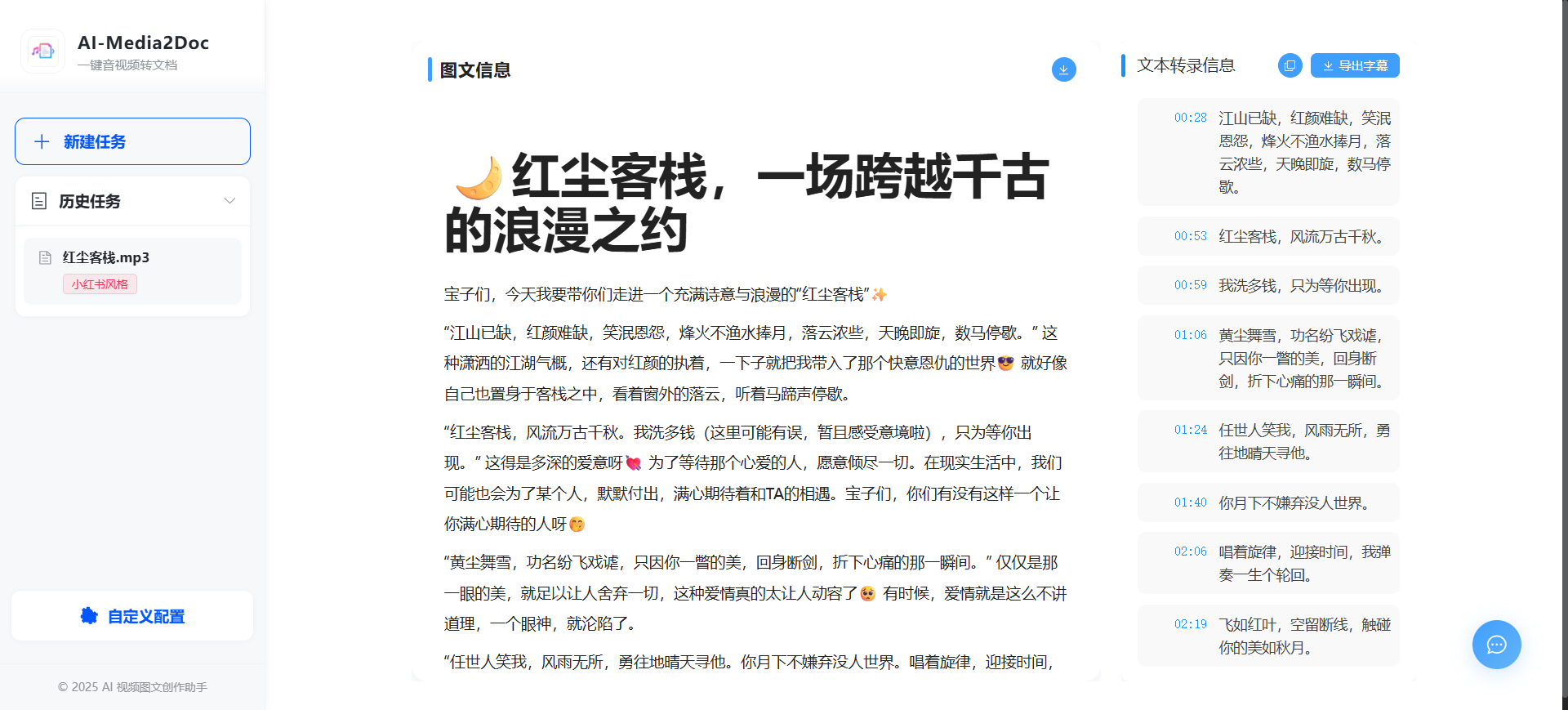
部署过程爬的坑
防火墙端口放开
如果使用的是云服务器,请至安全组开放目标端口。
SharedArrayBuffer is not defined
因为浏览器的安全策略限制会报这个错,解决方法就两个:
不使用ip或这域名访问,使用localhost
使用域名+https
因为我是部署在服务器的,所以用第二种方案。
服务器部署前后端分离的调用问题
因为 AI-Media2Doc 是前后端分离的形式,所以服务器部署的情况下,调用后端不可能用localhost的形式,所以要改 AI-Media2Doc-0.3.0/frontend 目录下的 .env.development 。
# API 服务基础URL(开发环境)
VITE_API_BASE_URL=https://xxx.xxx.cnnginx基础认证
因为目前这个访问是没有权限的,对于暴露在公网的服务比较不安全,所以做个nginx基础认证。详细的可以看nginx官网教程。
密码文件生成
echo "ai:$(openssl passwd -apr1 '6321321480')" > .htpasswd